
今、多くのサイト運営者が抱えている悩みがあります。それは、「新しく作ったページがGoogleにインデックスされない」、「インデックスされるのが遅い」という悩みです。今回は何故、新しく作ったページがGoogleにインデックスされないのか、インデックスされるのが遅い原因と、解決策について解説します。
目次
Googleはリンクを辿って新しいページを発見し、インデックスする
GoogleはGoogle検索に登録されているページからのリンクを辿って新しいページを発見します。そのため、新しく作ったページをGoogleにインデックス(登録)してもらうには自社サイト内にあるすでにGoogle検索にかかっているページからリンクを張るだけで十分です。
しかし、Googleは毎日生まれる無数のウェブページを発見する作業をしているため、すぐに自社サイト内に追加した新しいページを見に来てくれるとは限りません。何年も前から運営されていてたくさんのキーワードで上位表示しているサイトの場合は数日以内に新しいページをインデックスしてくれますが、新しくできたばかりのサイトやあまり多くのキーワードで上位表示してない人気度の低いサイトの場合は数週間から数ヶ月かかることがあります。

そのため、最近は多くのサイト運営者が、Googleによるインデックスが遅いという悩みをかかえるようになってきています。以前は新しいページを作れば数日以内にインデックスされるのが普通でしたが、最近では数週間から数ヶ月もかかるケースが増えています。こうした悩みを解決するためにはサーチコンソールの通知機能を使うことが有効です。
Googleに新しいウェブページをインデックス(登録)してもらうための通知ツールは、サーチコンソールに2つ用意されています。
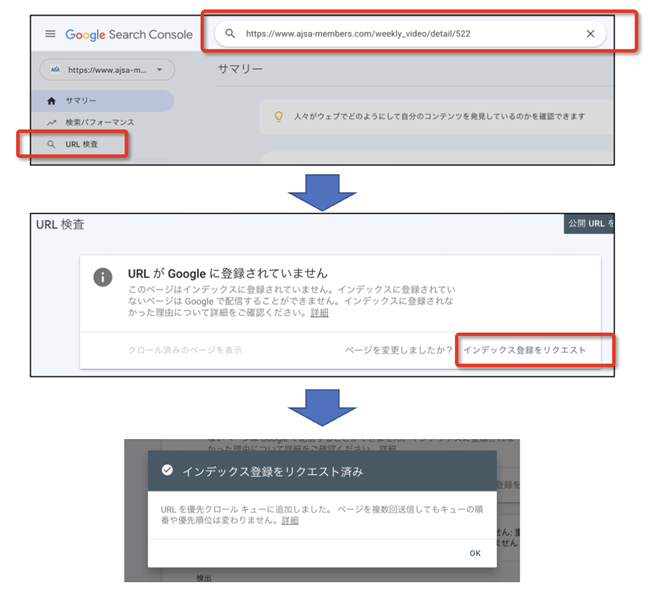
① URL検査
新しいページのURLを「URL検査」というところに入力し、Enterを押します。その後に「インデックス登録をリクエスト」というリンクが表示されるのでそのリンクをクリックすると登録リクエストの手続きが完了します。
② サイトマップファイルへの追加
URL検索の機能は便利ですが、1日あたりの登録リクエスト数には制限があります。
また、「インデックス登録をリクエスト」というリンクを押した後に数分待つことがほとんどです。
一度に多数のページの登録リクエストをしたい場合や、リンクを押した後に待つ時間を節約したい場合は、サイトマップファイルを作成し、そこに新しく作った記事ページのURLを追加することが効率です。
《サイトマップファイルに記述されたソースコードの例》

サイトマップファイルの追加方法については第1章で解説しているのでそちらを参照してください。
このようにサーチコンソールで自社サイトに追加した新しいページの存在を通知することにより、Google検索と、提携先のYahoo!JAPANにより早く、確実に登録することが可能になります。
しかし、それでも稀にサイト内の一部のページがインデックスされないことがあります。
サイト内のどのページがインデックスされていて、どのページがインデックスされていないか、そしてインデックスされなかった理由は何かを知るには、サーチコンソールの「インデックス作成」→「ページ」を選択して「ページのインデックス登録」という画面を見ます。
《「ページのインデックス登録」の画面》
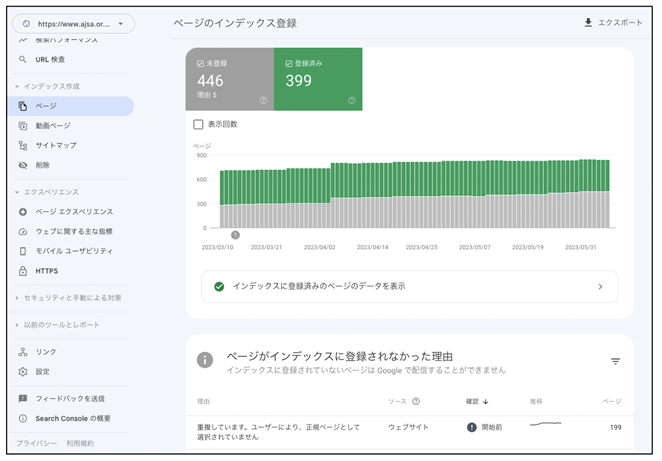
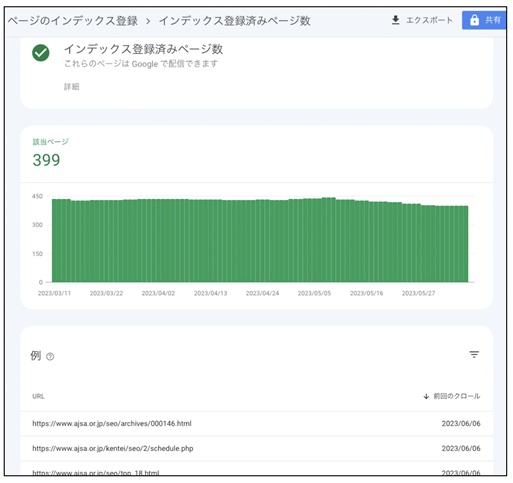
この画面の「インデックスに登録済みのページのデータを表示」を押すとインデックス登録されたページの一覧が表示されます。
《「インデックス登録済みページ数」の画面》
そして、「ページのインデックス登録」という画面の下の方を見ると、何故ページがインデックスされなかったかの理由が表示されます。
《「ページがインデックスされなかったかの理由」の例》
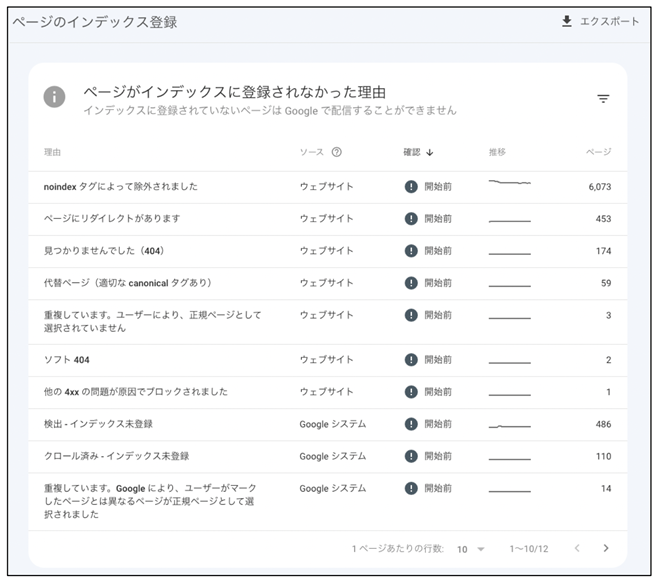
それぞれの理由をクリックするとその理由によってインデックスされなかったページの一覧が表示されます。
《「noindex タグによって除外されました」のページ例》
ページがインデックスされない理由
ページがインデックスされない理由は色々ありますが、代表的なものとしては次のようなものがあります。
① 他のページのコンテンツと重複しているから
Googleはサイト内に同じ内容、または似た内容のページを発見した場合、それらのページをインデックスしません。理由は、検索結果ページの品質を維持するためです。似た内容のページを1つのサイトから複数検索結果ページに表示すると検索結果ページの質が落ちてしまいます。ユーザーは検索結果ページにユニークな内容のページが表示されることを期待しているからです。
・重複しています。ユーザーにより、正規ページとして選択されていません
・重複しています。Google により、ユーザーがマークしたページとは異なるページが正規ページとして選択されました
というメッセージが表示されていたら、サイト内にある他のページとコンテンツが重複している可能性が高いので、それらのページの内容を確認して次の対策のいずれかを講じましょう。
(1)重複を解消するためにコンテンツを編集する
(2)ユーザーにとって不必要なページなら削除する
(3)noindexタグをページに記述して、インデックスをしないように申請する
(4)robots.txtを使ってクロールを回避する
(5)canonicalタグをページに記述して正規URLを申請する
(1)重複を解消するためにコンテンツを編集する
サイト内にあるページ数は少ないよりも、多いほうがSEOにはプラスになります。ページが多いほうが検索にかかる機会が増え、検索にかかる機会が増えればサイトのアクセス数が増える機会が増すからです。
コンテンツが重複しているページを発見したら内容を確認して、重複するコンテンツを全て削除できれば削除するか、削除できる部分があればその部分を削除して、オリジナルのコンテンツを追加しましょう。そうすることによってそのページのオリジナル性が高まり重複性が低下してインデックスされる可能性が高まります。
(2)ユーザーにとって不必要なページなら削除する
重複が指摘されたページを確認した時に、そのページはサイトを訪問するユーザーにとって不必要な場合は思い切って削除しましょう。
Googleのクローラーには「クロールバジェット」というものがあります。クローラーとは、検索エンジンが検索結果を表示するためにWebサイトの情報を収集する自動巡回プログラム(ロボット)のことです。
クロールバジェットとは、ウェブ上に存在するサイト1つ1つに割り当てられるクローラーが巡回する時間配分のことを意味します。Googleはウェブ上に存在する全てのウェブサイトを平等に扱っているわけではありません。重要性が高いと判断したサイトには頻繁にクロールをし、かつ長時間クロールしますが、重要性が低いと判断したサイトをクロールする頻度は低く、1回のクロールに割り当てる時間、またはページ数は少なめに設定しています。
ユーザーにとって不必要なページをサイト内に残しているとクロールバジェットを無駄に使うことになり、クローラーにインデックスして欲しいページをクロールする時間を失うことになります。
(3)noindexタグをページに記述して、インデックスをしないように申請する
noindexタグは、ある特定のページが検索エンジンによってインデックスされないようにするためのメタタグです。これは、特定の情報を非公開に保つ必要があるときや、重複コンテンツ問題を避けたいときなどに利用されます。
HTMLの
セクション内に次のような形式で記述します:![]()
このタグをページに追加すると、そのページは検索エンジンによってインデックスされなくなります。なお、robotsの部分は、特定の検索エンジンをターゲットにすることもできます。例えば、Googleだけをターゲットにする場合は、以下のようにします:
![]()
(4)robots.txtを使ってクロールを回避する
robots.txtはウェブサイトのルートディレクトリに配置するテキストファイルで、検索エンジンのクローラ(ロボット)に対し、どのURLパスをクロール(巡回)すべきか、または避けるべきかを指示するものです。以下に、一部のパスをクロールから回避するための基本的な手順を示します。
ウェブサイトのルートディレクトリに robots.txt ファイルを作成します。例えば、自社サイトのURLが http://www.aaa.com の場合、robots.txt ファイルは http://www.aaa.com/robots.txt にアップロードします。
このファイルには、以下のような形式でクローラの動作を制御する指示を書きます。
User-agent: [クローラ名]
Disallow: [クロールを禁止したいパス]
User-agent: は対象とするクローラを指定します。すべてのクローラに対して同じルールを適用したい場合は、User-agent: * を使用します。
Disallow: はクロールを禁止したいURLパスを指定します。全てのパスを禁止したい場合は、Disallow: / を使用します。
例えば、自社サイト上の http://www.aaa.com/members ディレクトリのクロールをすべてのクローラから回避したい場合、以下のように robots.txt を設定します:
User-agent: *
Disallow: /members/
この設定により、http://www.aaa.com/private ディレクトリ下のすべてのページがすべてのクローラから回避されます。
この方法を用いることにより、クローラーにコンテンツが重複しているページを無視してもらうことができます。
(5)canonicalタグをページに記述して正規URLを申請する
canonicalタグ(以下 カノニカルタグ)とは、ウェブサイト内でコンテンツが重複している、もしくは内容が極めて似ているURLが複数存在する場合に、評価してほしいURLがどれかを検索エンジンに示すために用いるタグです。
ウェブサイトには、やむを得ない理由で重複・類似コンテンツが発生する場合があります。例えば、次のようなものが挙げられます。
・同じコンテンツを別々のデバイスで公開している場合
・同じコンテンツを別々のURLで公開している場合
・同じコンテンツを別々の言語で公開している場合
このような場合、検索エンジンはどのURLを評価すべきか判断できません。そこで、カノニカルタグを使用して、評価してほしいURLを指定することで、検索エンジンが正しく評価を行えるようにすることができます。
カノニカルタグの記述方法は、次のとおりです。
以下のように
② コンテンツの品質が低いから
Googleは品質が低いコンテンツの掲載されたページをインデックスしないようにしています。ユーザーにとってメリットが無い低品質ページが検索結果ページに表示されてユーザーをがっかりさせないためです。
そのため、サイト内に品質が低いコンテンツが掲載されているページがあるとそれらのページはインデックスされなくなります。
コンテンツの品質が低いためにインデックスされなかったことを示すメッセージには次のものがあります。
・検出 – インデックス未登録
・クロール済み – インデックス未登録
・ソフト 404
これらのメッセージが表示されたらこれらのメッセージが発せられたページの一覧を見てコンテツを見直して品質を高める必要があります。品質を高めるには、他のサイトや、自社サイト内にある他のページには書かれていない独自性が高いコンテンツを増やすことや、読者が満足できるまで詳しくそのページのテーマの事柄を説明する文章を追加する必要があります。
不完全な情報量では読者は満足しません。単に文字数を増やすという発想ではなく、読者が納得できる量の説明をするという発想が必要です。こうしたやり方で品質を高めることができない場合は、重複コンテンツの解消策と同様に次の対策のいずれかを実施しましょう。
(1)ユーザーにとって不必要なページなら削除する
(2)noindexタグをページに記述して、インデックスをしないように申請する
(3)robots.txtを使ってクロールを回避する
③ サイト運営者が自分でインデックスされないように設定している
サイト運営者が誤って、本来インデックスして欲しいページにnoindexタグを張っていたり、robots.txtでクロールを回避していることがありますので、そうしたことをしてないかを確認しましょう。そしてそのことが原因だとわかったら速やかにそうした誤った処理を解消すれば、他に問題が無い限りはインデックスされるようになります。
以上が、ページがインデックスされない原因とインデックスさせる方法についてです。少しでも心当たりのあるところを見つけたらすぐに対応しましょう。そうすることにより早期の回復が目指せます。